Amazon Elastic Kubernetes Service
개요
4.RESOURCE/KNOWLEDGE/AWS/AWS에서 제공하는 관리형 쿠버네티스 서비스.
컨트롤 플레인에 대한 제어는 aws에서 맡고, 사용자는 워커 노드들을 사용할 수 있게 된다.
이를 통해 편하게 운영 단점을 빼고 쿠버네티스를 도입하며 얻을 수 있는 장점들만 가져갈 수 있게 된다.
쉽다는 이야기는 안 했다
비용
클러스터를 구축하는 비용은 시간 당 0.1달러로, 한 달 정도 지나면 60달러쯤 된다.
이 클러스터는 컨트롤 플레인 사용료라 보면 되겠고, 여기에 리소스를 어떻게 배치할 것인가는 커스텀을 할 수 있는데, 이 리소스들은 전부 비용이 발생한다.
가령 ec2 t5.large 3대, vpc에다가 모니터링 등의 기능들을 한꺼번에 이용해 구축하면 관련 리소스 비용이 전부 발생하게 된다는 것이다..
그래서 싸면서도 싸다고만 볼 수는 없다.
특히 클러스터에서는 사용자가 아무 짓도 하지 않더라도 필연적으로 네트워크 비용이 발생할 수밖에 없다.
허브앤스포크 패턴으로 인해 kube-apiserver는 지속적으로 kubelet과 kube-proxy와 통신을 하게 되기 때문이다.
물론 이런 비용들을 최적화를 하는 방법이 다 있기는 하나, 무작정 비용이 싸다고만 볼 수 없다는 점은 꼭 인지해야 한다.
개인적으로 집에서 클러스터를 구축해보고 느낀 점은, 사실 0.1 달러 내면서 클러스터 운영 소요를 줄이는 것 매우 혜자인 것 같다.
예상치 못하게 CoreDNS가 작동하지 않거나, 로깅을 하는데 어려움이 있었다.
쿠버의 장점이 웬만한 모든 걸 딸깍 배포하고 그 이후 알아서 관리되도록 할 수 있다는 것이지만, 그 이면에 따로 설정을 해주어야 하거나 이슈가 발생하는 경우가 많았다.
버전에 따른 비용

eks는 쿠버네티스의 버전을 항상 따라간다.
그래서 3개월 주기로 나오는 새 버전을 따라가며 해당 버전을 사용할 수 있게 해준다.
그런데 이때 주의할 것이 클러스터 운영자가 버전을 업데이트를 느리게 할 경우이다.
aws에서는 기본적으로 최근 4개의 버전에 대해서만 위의 비용으로 산정한다.[1]
(구체적으로는 새로 나온 버전에 대해 14개월 유지해줌)

그 말인 즉슨, Kubernetes v1.32 - Penelope 버전이 나온 현재 eks 1.27을 쓰고 있다면 시간당 비용이 6배가 늘어나는 것이다;;
이걸 확장 지원이라고 부르는데, 그것도 최대 12개월 간만 지원해준다.
구조
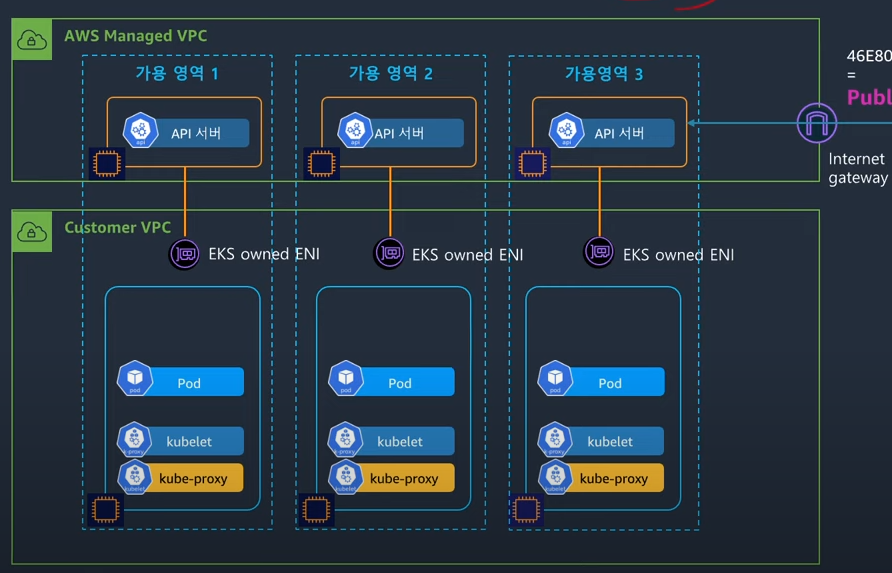
eks를 만들면 컨트롤 플레인 영역은 사용자의 vpc와 분리된 영역에 생기게 된다.[2]
그리고 컨트롤 플레인은 aws에서 관리되는 vpc에 배치되고, 사용자들은 데이터 플레인을 관리할 수 있게 된다.
이때 컨트롤 플레인와 데이터 플레인의 통신은 eni를 통해 이뤄지게 되는데, 이것은 사용자가 만드는 게 아니라 aws 측에서 알아서 만들어서 관리해준다.
그래서 eks owned ENI라고 부른다.
워커 플레인의 서브넷을 퍼블릭에 두느냐, 프라이빗에 두느냐를 설정하는 것이 가능하다.
애드온
eks에는 다양한 애드온을 설치할 수 있다.
가령 cni, csi, 모니터링 도구 등 쿠버네티스 환경에서 기본적으로 세팅을 해야 하지만 운영자의 몫으로 남겨진 많은 것들을 편하게 설치할 수 있도록 aws에서 추적 관리 제공을 해주는 것이다.
aws eks describe-addon-versions --query 'addons[].{ Name: addonName, Owner: owner Publisher: publisher, Type: type}' --output table --kubernetes-version 1.31
이런 식으로 클러스터 버전 별로 지원해주는 애드온이 무엇이 있는지 확인할 수 있다.

어차피 eks를 콘솔로 설치한다면 이렇게 볼 필요는 없겠지만, 만약 테라폼이나 eksctl로 사전 세팅을 하고자 하는 경우에는 이 이름들을 사용해야 하기에 유용하다.
aws eks describe-addon-versions | jq ' .addons[] | { Addon: select( .addonName? == $ADDON_NAME).addonName , CompatibleVersions: [ .addonVersions[] | select(.compatibilities[]? | .clusterVersion == $CLUSTER_VERSION) | .addonVersion ] }' --arg CLUSTER_VERSION "1.31" --arg ADDON_NAME "kube-proxy"
aws 쿼리 짜다가 그냥 jq로 처리했다..
(일부러 한 줄로, 그것도 맨 끝 문자들만 바꿔서 수정할 수 있도록 열심히 만들었는데 개추 좀)
아무튼 내가 설치하고자 하는 클러스터 버전에서 사용할 수 있는 각 애드온 버전을 보고 싶다면 이렇게 넣어준다.

웬만해서 가장 최근 것을 사용하겠지만, 그래도 버전도 확실히 지정해서 하고자 한다면 유용할 것이다.
또한 이 버전을 알아야 하는 이유가 한 가지 더 있다.
ADDON_NAME=eks-pod-identity-agent
ADDON_VERSION=v1.3.5-eksbuild.2
aws eks describe-addon-configuration --addon-name $ADDON_NAME --addon-version $ADDON_VERSION | jq '.configurationSchema' -r | jq
프로비저닝 툴을 이용해 애드온을 세팅할 때, 사전에 세팅할 값들을 알기 위해서는 설정 스키마를 꺼내야만 한다.

이때는 버전을 명시해서 넣어야 하기에 사용할 버전을 알아두면 도움이 된다.
물론 자동화 없이 그냥 콘솔로 낑낑하고 싶으신 분들이 있으시다면 그대로 하시면 됩니다
처음 보면 이 양식이 익숙하지 않을 텐데, ref라 쓰인 부분을 채우는 게 핵심이라고 보면 된다.
가령 위의 양식에서는 최상단 ref가 "#/definitions/KubeProxy"라고 돼있다.
그렇다면 나는 당장 보이는 definitions블록 아래의 KubeProxy 양식에 맞춰서 설정을 작성하면 된다.
그럼 KubeProxy 블록의 properties에 해당하는 부분들이 내가 설정할 수 있는 부분들이 되는 것이다.
근데, 그 안에도 properties.ipvs에 또 ref가 있다.
그럼 이 부분은 또 해당 위치의 양식을 보고 작성하면 된다는 뜻이다.
{
mode: iptables,
ipvs:{
scheduler : rr
}
}
다음이 kubeproxy 애드온 설정 예시가 되겠다.
(그냥 단순히 찍어서 만들어본 예시라 안 될 수도 있는데, 이런 식이란 것만 알면 활용할 수 있을 것이다.)
결국 properies 안의 필드를 우리가 설정할 수 있고 이것들에 대해서는 타입과 방식이 이미 다 제시된 형태의 json 파일이란 것이다!
컨트롤 플레인에 대해
그렇다면 이들이 어떻게 컨트롤 플레인을 대하는지 조금 더 구체적으로 알아보자.
온프레미스 클러스터와의 비교할 만한 지점들을 세심하게 짚어본다.
위의 사진에 나와 있듯이 HA를 위해 컨트롤 플레인은 다중 가용 영역에 배치된다.
구조
컨트롤 플레인은 내부에 다양한 aws 리소스를 가지고 있다.[4]
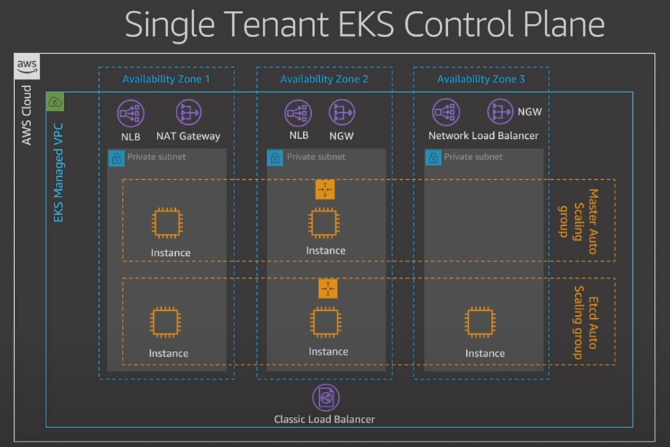
19년도 당시 자료인데, etcd와 기타 컴포넌트를 분리하는 ha 구성을 했다.
그리고 etcd 앞에 로드 밸런서를 배치하여 라우팅을 수행했었다는데, 이건 최근에는 해당하지 않는 내용이다.
api서버와 etcd는 사이에 로드밸런러서를 두지 않고 쿠버네티스 아키텍쳐 상의 흐름 그대로 통신한다.
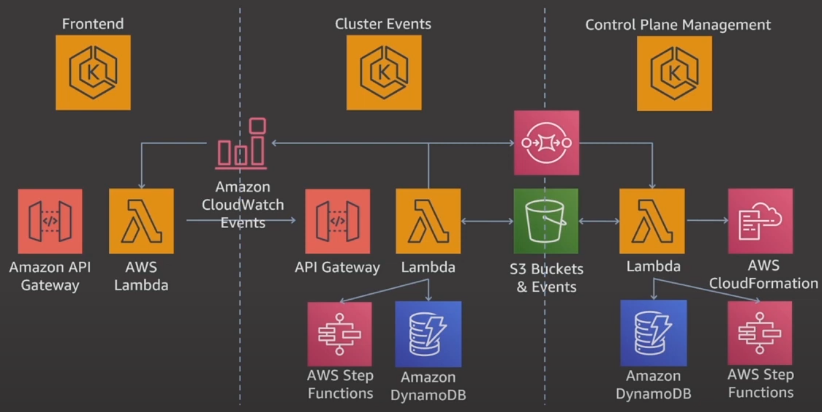
이거는 eks를 운영하는데 있어서 aws에서 동작하는 추가적인 리소스들이다.
몇 개는 생략돼있을 텐데, 뭐 우리는 이것들을 볼 일은 절대 없다.
클러스터 액세스 엔드포인트
api 서버와 통신하는 주체는 크게 두 가지로 분류된다.
- 쿠버네티스를 사용하고자 하는 우리같은 사용자
- 클러스터 구동 레벨에서 동작하는 각종 컴포넌트(라고 해봐야 kubeproxy, kubelet이 전부)
- 컨트롤러 매니저 등은 어차피 같은 인스턴스에 배포가 되어 있을 것이기에 우리가 상관할 바는 아니다.
여기에 대해서 3가지 모드를 사용할 수 있다.
퍼블릭
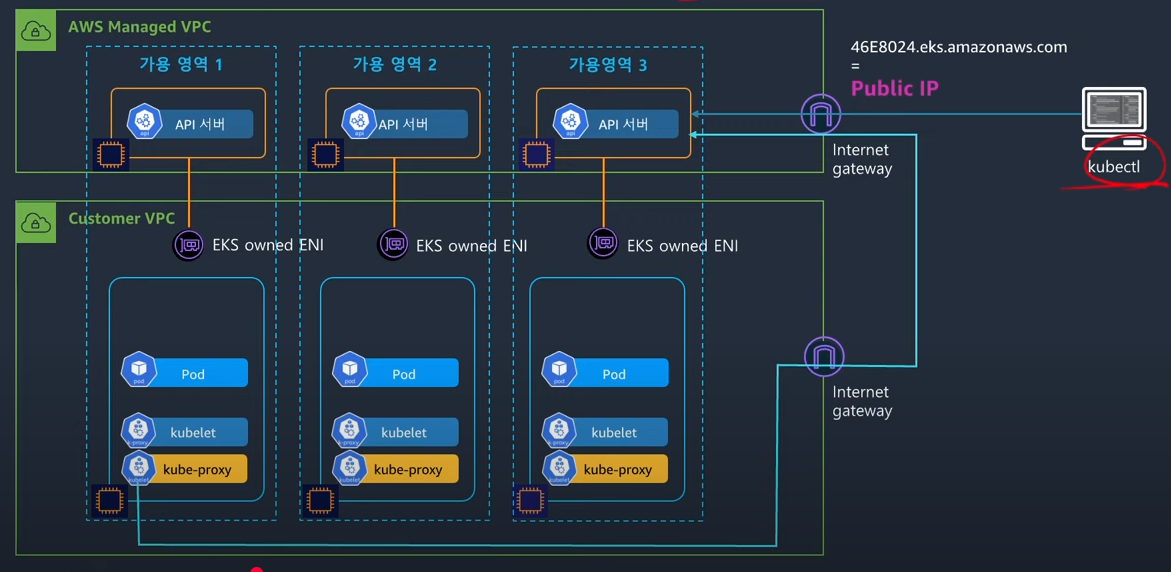
모든 요청이 퍼블릭 ip를 통해 이뤄진다.
즉, kubelet에서 api 서버로 가는 요청도 퍼블릭을 나갔다 들어온다..
위 그림의 데이터 플레인을 보면 kube-proxy의 트래픽인 파란 줄이 igw를 타고 나가서 다시 igw를 타고 api 서버로 접근하는 게 보인다.
달리 말해서, igw 트래픽 아웃바운드 요금이 발생하게 된다.
여기에 노드들이 프라이빗 서브넷에 있었다면 nat를 타는 비용까지 발생할 것이다.
참고로, 컨트롤 플레인에서 워커 노드로 향하는 통신(클러스터 정보 수집, 혹은 exec이나 logs등의 요청으로 이뤄지는 트래픽)은 퍼블릭 모드여도 eks owned eni를 타고 온다.
프라이빗
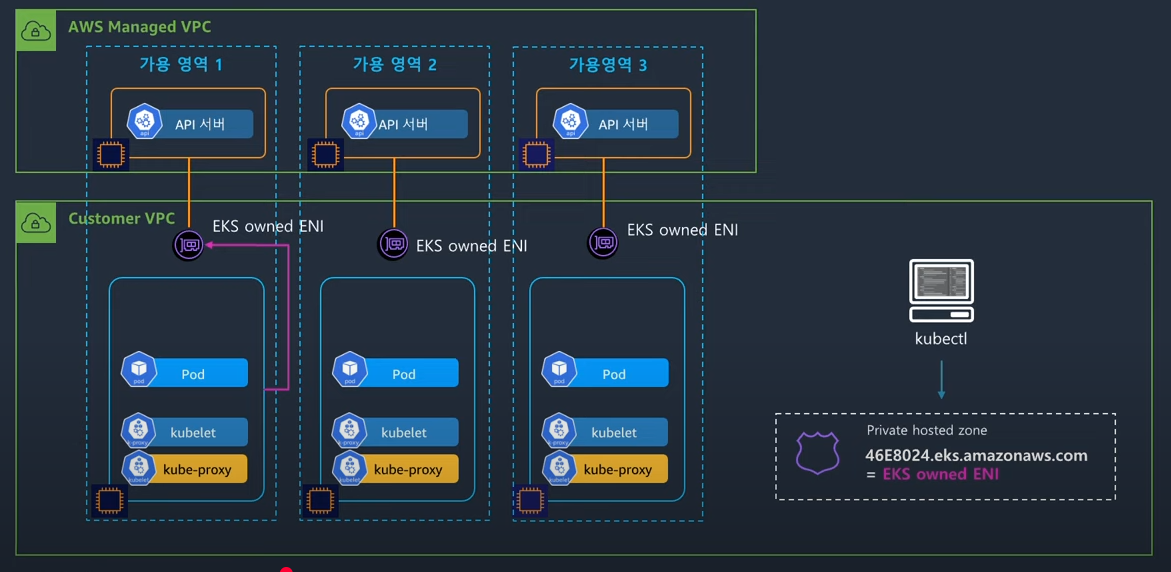
모든 통신은 프라이빗 ip를 통해서만 이뤄진다.
워커 노드의 요청인 분홍 줄이 eni를 타고 간다.
그래서 만약 해당 요청이 다른 az로 가는 경우에 발생하는 크로스존 비용만 발생할 것이다.
그런데 클라이언트의 퍼블릭 요청도 막힌다.
즉, 클라이언트가 접근을 하고 싶더라도 무조건 바스티온 같은 별도의 설정을 넣어야만 한다.
그림은 같은 vpc에 인스턴스를 띄워서 접근을 하는 그림이다.
혼용
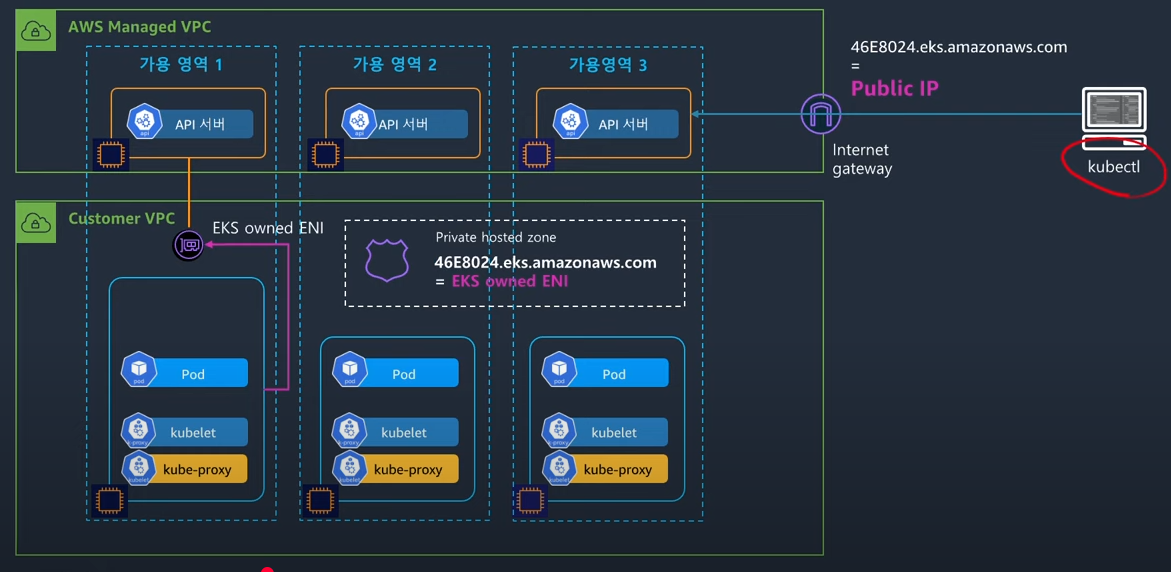
위의 짬뽕 버전으로, 클라이언트만 퍼블릭 ip를 사용하는 구조이다.
정말 필요한 외부 트래픽만 퍼블릭 ip를 사용하니 상대적으로 안전하고, 비용도 효율적이다.
이 방식은 DNS를 이용해서 구현된다.
그림처럼 46~.aws.com의 주소에 대해서, Amazon Route53이 데이터 플레인의 vpc에서는 프라이빗 ip를 반환해준다.
그 외의 장소에서의 요청은 전부 퍼블릭 ip를 반환하는 것이다.
이러한 동작 방식을 스플릿 호라이즌 DNS라고 부른다.
이를 통해 vpc 내의 컴포넌트들은 내부 eni를 타고 api 서버와 통신을 할 수 있게 된다.
지피티한데 여러 비용관련 질문을 했다.
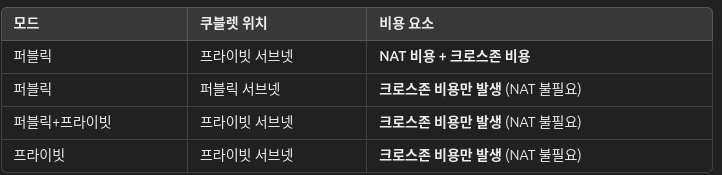
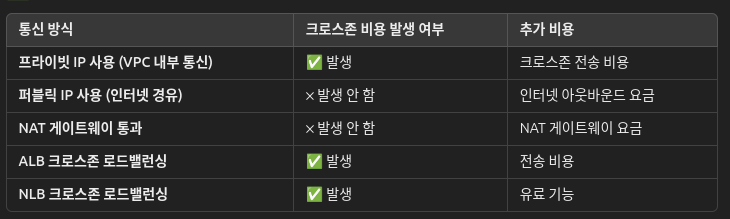
지피티 친구 칭찬해용
워커 노드 그룹
우리가 세팅할 수 있는 데이터 플레인에 대해서, 다양한 선택지가 제공된다.[5]
그냥 ec2를 노드로 쓸 수도 있고, 서버리스를 쓰는 것도 가능하다.
여기에 노드를 어떻게 관리할 것인지에 대한 선택지도 추가해서 다음의 유형들을 제공해준다.
여기에서 유의할 것이 무조건 하나만을 선택해야 한다는 것은 아니다.
아래 유형들은 혼용해서 활용하는 것이 가능하다.
자체 관리형 노드(self-managed node)
그냥 직접 ec2를 관리하는 것을 말한다.
흔히 온프레미스에서 하나의 컴퓨터를 워커 노드로 두는 것과 완전히 똑같다.
그래서 노드 스케일링 등의 작업은 전부 직접 담당해야 한다.
관리형 노드 그룹(managed node group)
위의 방식보다는 조금 더 aws에서 노드 관리를 도와주는 방식이다.[6]
노드들을 노드 그룹이라는 상위 집합으로 묶고, 노드 스케일링, 업데이트 등의 작업의 편의성을 더할 수 있는 동작을 지원해준다.
대체로는 이걸 많이 사용하는데, 순수 자체 관리보다는 운영 소요가 적고 그렇다고 비용이 발생하는 것도 아니기 때문이다.
노드 자동 복구 등의 작업도 수행해주니 굳이 안 쓸 이유가 없다.
EKS Auto Mode
AWS Fargate
Fargate를 이용해 서버리스 컴퓨팅 자원을 지원한다.
사용한 만큼만 비용을 지불하니 좋다고도 말할 수 있지만, 사실 쿠버를 활용하는 환경은 대체로 상시 운용이 주목적이다보니 잘 들어맞지는 않는다고 생각한다.
그러나 다른 유형과 혼용이 가능하기에 일시적인 잡을 진행하는 케이스에 대해서만 fargate를 쓴다던가 하는 식의 운영을 해볼 수는 있겠다.
파게이트에 리소스를 배치할 때는 쿠버의 kube-scheduler와 별도의 스케줄러가 동작하며, 이것은 Admission Webhook을 통해 알아서 요청이 수정되어 파게이트 스케줄러가 담당하게 된다.
이 스케줄러가 알아서 aws의 관리 구역에 배포를 진행해준다.
실습 중인데 너무 오래 걸려서.. 문서 정리를 하면서 기다린다.
그래서 파게이트를 어떻게 활용하는가?[7]
파게이트 프로필을 먼저 지정한다.
그러면 파게이트 컨트롤러가 돌아가게 되는데, Admission Webhook이 발동하여 파게이트 스케줄러로 넘어가서 스케줄링이 이뤄지게 된다.
이렇게 만들어지는 파드는 어떤 특징을 가지는가?
- 자체 격리 경계
- 로드밸런서는 무조건 ip를 대상으로만 연결될 수 있다.
- 데몬셋은 지원되지 않는다.
- hostnetwork 모드, priviledged 같은 노드와 관련된 설정 불가능
- gpu 불가
파게이트 프로필에서 보조 cidr 블록을 지정할 수 있다.
aws cni만을 사용할 수 있다.
ebs csi 컨트롤러가 동작은 하지만, 이것도 데몬셋으로 되는 건 아니다.
잡이 완료되도 파드가 사라지는 것이 아닌 이상, 자원은 남게 되고 당연히 비용이 발생한다.
기존 노드가 존재한다면 파게이트 파드는 해당 노드의 보안 그룹을 사용하게 된다.
실행 iam을 따로 설정해야 한다.
파게이트의 파드는 프라이빗 서브넷에만 배치된다.
eksctl create fargateprofile \
--cluster my-cluster \
--name my-fargate-profile \
--namespace my-kubernetes-namespace \
--labels key=value
eksctl로 파게이트 만들기
kubectl patch deployment coredns \
-n kube-system \
--type json \
-p='[{"op": "remove", "path": "/spec/template/metadata/annotations/eks.amazonaws.com~1compute-type"}]'
kubectl rollout restart -n kube-system deployment coredns
이렇게 만들었을 땐 상관 없으나, 다르게 만들었을 때는 CoreDNS 설정을 업데이트해야 한다.
프로필이 만들어졌다면, eks.amazonaws.com/fargate-profile: my-fargate-profile 라벨을 파드에 달아주면 된다.
프로필은 수정이 안되므로, 삭제했다가 다시 만들었다.
프로필 구성요소
- 파드 실행 역할
- 파게에서는 kubelet이 사용자 대신 aws api를 호출한다.
- 가령 ECR에서 이미지를 가져올 때라던가.
- 이에 대해서 파드 iam을 지정해야 한다.
- 서브넷
- 셀렉터
- 네임스페이스와 라벨이 필요하다.
파게이트에 실행할 파드에 대해
리소스를 잘 제한하는 게 중요할 것이다.
cpu, 메모리 등.

리소스 테이블은 이렇게 된다.
여기에 kubelet 등의 실행 리소스 때문에 자의적으로 256 메가가 추가적으로 할당되어 실행된다.
이 테이블에 따라, 적절하게 올림 처리되어 파게이트의 리소스가 정해진다.
알아서 Amazon Elastic File System가 탑재된다.
기본으로 20기비 바이트가 탑재되는데, ephemeral-storage 설정으로 175기비 바이트까지 높일 수 있다.
동적 프로비저닝이 불가능하다.
Karpenter
aws에서 만든 오픈소스로, Karpenter는 유연한 클러스터 오토스케일링을 지원한다.
사용법도 간단하고 비용을 효율적으로 관리하는 기능이 많아 대부분의 환경에서 사용하는 것 같다.
대충 이런 작업을 해준다.
클러스터 내 리소스가 부족하면 현재 필요한 만큼(unscheduled)의 리소스를 계산하여 이에 맞는 인스턴스를 새로 만들어준다.
그리고 여러 노드에 리소스가 분산 배치돼어 비용이 불필요하게 발생한다면 한 노드로 리소스를 집중 배치해준다.
하이브리드 노드(Amazon EKS Hybrid Nodes)
온프레미스의 노드를 eks에 혼용하여 사용하는 방식이다.[8]
인스턴스에 대해
인스턴스 이미지
aws에서는 쿠버 클러스터를 위한 인스턴스 이미지(Amazon Machine Image)를 제공한다.[9]
보안, 네트워크 관련 최적화가 조금 더 되어있다고 한다.
이중에 보틀로켓(Bottlerocket)이라는 놈이 있는데, 컨테이너 워크로드를 실행하기에 최적화된 리눅스 배포판이다.[10]
컨테이너를 안전하게, 효율적으로 실행하는 것과 관련된 소프트웨어 컴포넌트들만이 들어가 있다.
그러니 같은 스펙의 리소스에서 실행하더라도 더 많은 컨테이너를 감당해내는 동시에 공격 표면도 줄일 수 있다.
재밌는 것이 필요한 환경 구축에 있어서 각종 변형 가능성을 둔다는 것.
가령 쿠버 특정 버전에 최적화된 환경, vm을 돌리는 환경 등을 구성하는데 도움을 준다.
아주 기본적인 이미지는 정해져 있고, 그 위에 각 버전에 맞는 필요한 모듈들을 얹는 구조이다.
업데이트를 동적으로 지원한다는 것.
인스턴스 유형
이건 사실 EC2에서 다룰 만한 내용이다.
그냥 일반적인 인스턴스랑, 스팟 인스턴스 지원한다 정도..
스팟 인스턴스는 언제 뺏길지 모르니 당연히 안정적으로 클러스터를 운영하기 위해서는 조금 고려할 요소가 많다.
정말 중요한 워크로드는 스팟 인스턴스에 올라가면 안 될 것이고, 인스턴스가 종료되기 이전의 이벤트를 통해 파드를 옮기는 핸들러가 필수적으로 필요할 것이다.
네트워크
aws cni
일단 eks에서는 자체적으로 aws CNI를 따로 제공해준다.
이 친구는 aws에서 리소스, 트래픽 추적을 용이하게 자체적으로 구성된 cni로서, 파드가 VPC의 ip 대역도 받게 한다는 장점이 있다.
달리 말해 그냥 노드에서 파드로의 접근이 별도의 설정없이 가능하게 된다.
이건 장점이면서도 단점인데, vpc의 ip 주소가 빠르게 소모될 여지가 있다.

이때 조금 알아야 할 게, ec2 인스턴스에는 붙일 수 있는 인터페이스의 개수가 정해져있다.
AWS CNI에서 더 자세히 다룬다.
loadbalancer
aws에서 제공해주는 ALB Controller가 있다.
몇 가지 설정을 조금 특이하게 할 수 있는 게 있는데, 대표적인 것이 모드이다.
보통 로드밸런서는 노드포트로 트래픽을 전달한다.
그러나 aws 로밸컨은 파드 ip로 바로 트래픽을 전달하도록 설정을 하는 것이 가능하다.
이 말은 달리 말해 로드밸런서가 각 파드가 위치한 노드의 위치를 이미 알고 있도록 설정된다는 것이렷다.
보안
EKS에서 보안이라 하면 크게 두 가지로 나뉜다고 볼 수 있다.
api 서버 보안
첫번째는 클러스터 조작을 하는 kube-apiserver에 대한 보안이다.
온프레미스 환경에서 api 서버를 접근하는 주체가 누구인지 검증하는 것은 전적으로 api 서버에서 관리된다.
그러나 EKS 환경에서는 조금 다른 방식을 제공하는데, AWS의 IAM에 있는 유저 정보를 바탕으로 인증을 하게 된다.
아무래도 AWS에서 api 서버를 관리하니, api 서버로 접근하는 사람을 인증하는 것 역시 AWS 차원에서 관리를 하는 것이 당연하다고 볼 수 있겠다.
다시 말해 시큐리티#1. 인증(Authentication) 단계를 전적으로 AWS에서 관리한다는 것이다.
(참고로 당연히 클러스터 내부에서만 활동하는, 서비스 어카운트의 인증과는 관련 없다.)
그렇다면 여기에서 한 가지 문제가 생기는데, 여차저차 AWS의 신원이 증명됐다고 쳐보자.
근데 어떤 IAM 유저인지 알았다고 해서 클러스터에서 해당 유저를 명확하게 식별할 수 있는가?
즉, AWS에서의 신원과 클러스터 내의 신원을 매핑시키는 과정이 api 서버 보안에서 핵심 관건이라고 할 수 있다.
사실 그냥 aws 차원에서 신원 검증이 끝났으면 그냥 그대로 클러스터 내부에서는 무슨 신원인지 상관 안 해도 되는 것은 아닐까?
가령 어차피 모든 인증된 유저는 클러스터 내에서 system:authenticated라는 그룹에 속하게 된다.
그럼 인증을 전적으로 aws에서 관리하고, 저 그룹에 속한 주체는 어떤 동작이든 가능하게 인가해준다던가 하면 안 되냐는 것이다.
말만 들어도 느끼겠지만, 그런 방식에는 문제가 있다.
api 서버 보안은 단순히 인증으로 끝나지 않기 때문이다.
인증 다음에는 인가 단계를 거쳐야 하는데, 여기에서는 클러스터의 신원이 사용되기 마련이다.
system:authenticated에 모든 권한을 부여하는 행위는 당연히 최소 권한 원칙을 준수하지 않는 위험한 행위이고 지양돼야 한다.
그렇기 때문에 인가를 적절하게 수행하기 위해서는 적절하게 클러스터의 신원으로 매핑하는 과정이 필요하다.
configmap
먼저 말하지만 곧 이 방식은 없어질 것이다.
이건 iam 신원과 매칭되는 클러스터 신원을 ConfigMap으로 관리하는 방식이다.

기본적으로 사용자가 클러스터 조작을 가할 때 다음의 과정이 일어난다.[11]
요약해서 흐름을 보겠다.
- 로컬에서는 STS로 임시 자격 증명을 얻어내고 이걸 이용해 api 서버에 접근한다.
- api 서버는 웹훅 토큰 인증 방식을 통해, aws-iam-authentication-server에 인증을 맡긴다.
- 참고로 aias 서버는 컨트롤 플레인에 위치해있을 거라, 일반 사용자가 확인할 수 없다.
- aias 서버는 받은 토큰을 이용해 IAM api와 통신해 AWS 상의 유저, 그룹 등의 신원 정보를 받아낸다.
- 신원 정보를 사전에 설정된 클러스터 내에서의 신원 정보와 매핑시켜 인증 단계를 통과시킨다.
이 마지막 매핑 단계에서 configmap에 저장된 정보를 바탕으로 클러스터 신원을 매핑시킨다는 것이 핵심이다.

이 컨피그맵의 경우, 저 roleArn으로 들어온 요청일 때 aias 서버는 username은 system:node:인스턴스 이름, 그룹은 system:nodes로 매핑을 시켜서 인증 단계를 통과시키게 되는 것이다.
매핑이 어떻게 돼야 하는지 자체는 운영자가 미리 세팅을 진행해야 한다.
aias는 매핑된 정보를 컨피그맵에서 불러와 적절하게 정보를 넣어주는 역할만 수행한다.
eksctl create iamidentitymapping --cluster $CLUSTER_NAME --username testuser --group system:masters --arn arn:aws:iam::$ACCOUNT_ID:user/testuser
이런 식으로 명령을 내리면 --arn에 있는 iam 유저가 username:group으로 클러스터 신원에 매핑된 정보가 컨피그맵에 저장된다.
단점
이 방식의 단점은 명백하다.
AWS에서는 위의 명령어와 같은 식으로 인증 설정을 조작하도록 이야기하지만, 일단 configmap은 쉽게 클러스터 내부에서 수정이 가능하다.
즉, 악성 내부 관리자가 인증 조작을 하는 것이 너무 쉽다.
여차하면 실수를 하는 것도 가능할 것이다.
물론 기록은 남겠지만, 이렇게 쉽게 휴먼 에러를 발생시킬 수 있는 방식 자체가 좋은 운영 방식이 아니다.
ConfigMap#immutable을 사용하는 방향도 생각할 수 있겠다.
그것도 그래봤자인 게, edit만 안 되는 거지 삭제했다 재생성하는 건 가능하기에 여전히 불안한 방식임에는 변함이 없다.
Access Entry

그래서 다음으로 나온 방식이 바로 Access Entry(진짜 이름 개대충 짓네)이다.[12]

이 방식은 eks api를 활용한 매핑 방식으로, 매핑 정보가 AWS 상에서 관리된다.
그러니 클러스터에서 실수를 한다던가 하는 일은 절대 발생하지 않고, 인증에 대한 관리 영역이 전적으로 AWS 위에서 성립한다는 장점이 있다.
초기 순서는 configMap과 동일하게 STS에서 임시자격증명을 얻어서 api 서버로 요청이 날아가는 것으로 시작한다.
그리고 웹훅으로 인증을 수행하게 되는데, 이때는 eks api를 호출해 요청의 aws iam 신원 정보가 어떤 클러스터 신원 정보와 매핑되는지 확인하고 이를 적용한다.
그런데 이 방식에서는 조금 차이점이 생긴다.
바로 인가에 대한 부분을 어느 정도 AWS에서 관리하게 된다는 것이다.
구체적으로는 AWS에서는 IAM 정책과 독립되는, 액세스 엔트리를 위한 관리형 정책을 따로 제공한다.[13]
쿠버네티스에서 기본적으로 세팅된 쿠버 RBAC#유저 중심 롤을 정책으로 규정해두었으며, 액세스 엔트리를 만들 때 이 정책들을 명시하여 사용할 수 있다.
즉, 액세스 엔트리는 클러스터 내의 그룹에 신원을 매핑시켜 클러스터 차원에서 인가를 수행하거나, 아예 관리형 정책을 통해 AWS측에서 인가까지 수행하게 하는 두 가지 방식으로 사용할 수 있다는 말이다.
# 관리형 정책에 매핑시키기
aws eks create-access-entry --cluster-name 클러 이름 --principal-arn IAM 유저
aws eks associate-access-policy --cluster-name 클러 이름 --principal-arn IAM 유저
--policy-arn arn:aws:eks::aws:cluster-access-policy/AmazonEKSClusterAdminPolicy --access-scope type=cluster
# 쿠버 그룹에 매핑시키기
aws eks create-access-entry --cluster-name 클러 이름 --principal-arn IAM 유저 --kubernetes-groups 쿠버 그룹
관리형 정책을 매핑시킬 때는 (귀찮지만) 두 번의 과정이 필요하다.

인가는 인가는 Authorization#Webhook으로 이뤄지는 것으로 추측된다.[14]

k auth can-i --list를 하게 될 경우 웹훅을 통해 이뤄지는 인가를 제외, 현재 유저가 할 수 있는 동작들을 확인할 수 있다.
그런데 관리자 권한을 가진 유저의 권한은 system:authenticated인 그룹이 가진 권한만 보이는 것이 확인된다.
이는 웹훅을 통해 인가가 이뤄지고 있다는 단서 중 하나이다.

두번째로, audit 로그를 보면 인가가 된 이유에 대한 내용이 명시된다.
어떠한 근거로 요청이 허가됐는지에 대한 내용이 담긴다.
여기에서는 클러스터 롤 바인딩과 클러스터 롤에 대한 이야기가 언급이 있으나, 이건 실제 클러스터에 존재하지 않는다.
이러한 인가 관련 사항이 AWS 측에서 관리되고 있음을 알 수 있는 대목이다.

그렇다고 위의 eks에서 관리해주는 정책들로만 인가 가능한 게 아닐까 걱정할 필요는 없다.
쿠버의 인가는 다양한 모듈이 있을 때 어느 한 모듈이 허가 결정을 내리기만 해도 요청이 통과되므로, 여전히 기본 쿠버의 RBAC도 작동한다.
관련한 워크숍에서도 클러스터 내에서 그룹 신원을 규정한 뒤에 액세스 엔트리에 그룹을 명시하면 해당 그룹에 대한 쿠버의 RBAC가 작동하는 것을 확인할 수 있다.[15]
aws 리소스 접근 보안
두번째는 클러스터의 워크로드가 AWS의 리소스에 접근하고자 할 때 적용되는 보안이다.
ALB Controller 같은 것들은 클러스터에서 구동되지만, 실제로 접근하는 리소스는 ALB로, AWS 상의 리소스이다.
그럼 이 컨트롤러는 무슨 자격과 권한으로 AWS 리소스에 접근하는가?
가장 간단한 방법은, 사실 해당 컨트롤러가 실행되는 인스턴스에 권한을 부여하는 것이다.
ec2 인스턴스가 로드밸런서에 대한 권한을 가진다면 그 인스턴스에 위치한 어플리케이션이 요청을 날릴 때는 해당 인스턴스의 자격을 얻어서 날리기에 이러한 방법이 유효하다.
다만 이렇게 하면 해당 인스턴스의 모든 어플리케이션이 관련한 권한을 가지게 되니, 최소 권한 원칙을 조금도 준수할 수 없다.
IRSA(IAM Roles for Service Accounts)

그래서 나온 것이 IRSA, 즉 서비스 어카운트를 IAM Role과 매핑시키는 방식이다.
클러스터의 모든 워크로드라면 기본적으로 가지게 되는 서비스 어카운트를 IAM 롤에도 매핑을 시킨다.

구체적으로는 서비스 어카운트에 어노테이션으로 매핑되고자 하는 iam 롤을 작성한다.[16]
eks.amazonaws.com/role-arn: arn:aws:iam::xxxx:role/eksctl-eks-oidc-demo-addon-iamserviceaccount-Role1-H47XCR6FPRGQ
이런 식으로 롤의 arn을 작성해주면 된다.
apiVersion: apps/v1
kind: Pod
metadata:
name: myapp
spec:
serviceAccountName: my-serviceaccount
containers:
- name: myapp
image: myapp:1.2
env:
- name: AWS_ROLE_ARN
value: arn:aws:iam::111122223333:policy/my-role
- name: AWS_WEB_IDENTITY_TOKEN_FILE
value: /var/run/secrets/eks.amazonaws.com/serviceaccount/token
volumeMounts:
- mountPath: /var/run/secrets/eks.amazonaws.com/serviceaccount
name: aws-iam-token
readOnly: true
volumes:
- name: aws-iam-token
projected:
defaultMode: 420
sources:
- serviceAccountToken:
audience: sts.amazonaws.com
expirationSeconds: 86400
path: token
그러면 실제 이 서비스어카운트를 사용하는 워크로드는 실행시점에 Admission Control#Mutating & Validating Admission Webhook이 걸리는데, 이때 다음의 두 가지 세팅이 이뤄진다.[17]
- 환경변수로 해당 role의 arn, web identity token 파일 경로가 주입된다.
- projected 볼륨으로 서비스어카운트 토큰을 받게 되는데, 이 토큰은 OIDC 프로토콜의 ID 토큰 형식으로 돼있다.
- 토큰 생성 자체는 api 서버 차원에서 알아서 해주는 작업이다.

뮤테이팅 웹훅은 이런 식으로 걸려있다.
스킵을 하도록 라벨을 달아두지 않으면, 모든 파드가 생성될 때 이 웹훅을 지나게 되는 것이다.
환경변수에 저 값이 들어가면 내부 컨테이너의 aws cli나 관련 라이브러리는 바로 STS로 요청이 날아간다.
이때 STS에서는 클러스터의 OIDC discovery 정보를 통해 신원이 제대로 검증된 것인지 체크한다.
신원 체크가 완료되면 해당 롤을 위한 임시 자격증명을 발급해주고, 이를 통해 aws의 리소스에 조작을 가할 수 있게 되는 것이다.

이건 테라폼 코드인데, 아무튼 해당 롤의 폴리시에서는 OIDC 검증을 할 수 있도록 AssumeRoleWithWebIdentity 액션을 취한다.
이렇게 하면 알아서 jwt 토큰의 값을 뜯어서 조건을 검사하게 된다.
꽤나 복잡해보이지만, 결국 운영자 입장에서 설정해야 하는 사항은 다음으로 정리된다.
일단 첫번째로, 클러스터 OIDC 설정이 돼있어야 한다.
- iam 롤 만들어두기
- 원하는 권한을 적고, oidc 인증을 통해 assume role을 할 수 있도록 정책 설정
- 워크로드가 사용할 서비스 어카운트에 iam 롤에 대한 어노테이션 달기
나머지는 클러스터와 aws 차원에서 동작이 이뤄지므로, 이것만 세팅해주면 된다!
단점
AWS 측에서 검사하는 것은 그저 해당 토큰이 정말 IDP 제공자로부터 서명됐는지일 뿐이다.
이 토큰을 가지고 요청을 보낸 자가 누군지, 그래서 어떤 권한을 가져가려고 하는지는 확인하지 않는다.
그래서 토큰이 탈취됐을 때, 누구든 해당 롤이 가지는 권한을 획득할 수 있다.
그리고 아무래도 불편하다보니 실무 환경에서 종종 *를 이용해 모든 서비스 어카운트에 요청을 풀어둔다던가 하는 일이 있다.
이러면 더더욱 보안은 취약해진다.
그리고 애초에 어노테이션을 활용하는 방식 자체가 실수가 발생하기 쉽기도 하고 또 번거로운 과정이다.
여기에 OIDC 세팅까지 해야 하니(딸깍이긴 하지만).. 불필요하게 인증서를 외부에 노출하는 꼴이기도 하다.
EKS Pod Identity
그래서 나온 것이 또 파드 아이덴티티.

간단하게 애드온을 설치하면, 이번에도 뮤테이팅 어드미션 웹훅이 적용된다.
그래서 세팅해둔 서비스 어카운트를 사용하는 워크로드가 있을 때, 마찬가지로 환경변수와 볼륨이 세팅된다.
그러나 다음 동작부터가 조금 다른데, 내부 프로세스가 aws 요청을 날릴 때 자격증명을 애드온으로 같이 세팅된 pod identity agent 데몬셋에 요청한다.
그럼 이 에이전트는 파드 아이덴티티 전용 assume role을 eks api로 날리고, aws 상에 미리 세팅된 것이 있다면 이를 토대로 임시 자격 증명을 발급해주는 것이다.
이를 통해 워크로드는 aws 리소스를 조작할 권한을 가지게 된다.

데몬셋으로 된 에이전트는 hostNetwork를 사용한다.
그렇기 때문에 작동되는 모든 노드가 기본적으로 위의 정책을 가지고 있어야 한다.

그럼 미리 세팅한다는 것은 어떻게 하냐, 이렇게 pod identity association을 만들어주면 된다.
iam 롤에는 필요한 권한 세팅만 해주면 되고, 여기에서 어떤 서비스 어카운트가 관련한 세팅을 받아야 하는지 연결해주면 된다.
eksctl create podidentityassociation \
--cluster $CLUSTER_NAME \
--namespace default \
--service-account-name s3-sa \
--role-name s3-eks-pod-identity-role \
--permission-policy-arns arn:aws:iam::aws:policy/AmazonS3ReadOnlyAccess \
--region ap-northeast-2
cli로는 이런 식으로 할 수 있다.

이 기능이 좋은 것이 태그를 기반으로 접근 가능한 리소스를 제한(ABAC)할 수 있다는 것이다.
노란 클러스터의 파드에는 노랑이라는 태그가 붙게 하면 해당 태그가 있는 리소스에만 접근이 가능한 방식이다.
위 사진으로 치면 위 컨테이너는 위의 AWS SM에만 접근이 가능할 것이다.
책임 영역
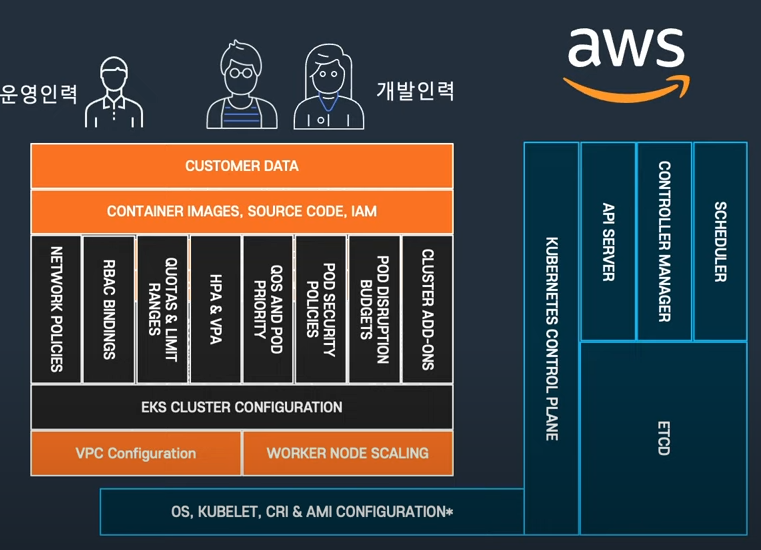
컨트롤 플레인의 영역 관리는 거의 전부 aws에서 책임을 진다.
그래도 클러스터 관리, vpc, 노드 스케일링 등은 운영자가 할 수 있도록 되어 있다.
여기에서 fargate면 worker node scaling도 aws가 담당하는 것이라 보면 되겠다.
관련 문서
| 이름 | noteType | created |
|---|---|---|
| EKS, ECS 비교 | knowledge | 2024-11-03 |
| Amazon Fargate | knowledge | 2024-11-03 |
| eksctl | knowledge | 2025-02-06 |
| Karpenter | knowledge | 2025-03-04 |
| EKS Automode | knowledge | 2025-04-23 |
| EKS 사전 준비 | project | 2025-02-14 |
| 1주차 - EKS 준비 | project | 2025-02-01 |
| 1주차 - 테라폼으로 프로비저닝, 다양한 노드 활용해보기 | project | 2025-02-05 |
| 2주차 - 테라폼 세팅 | project | 2025-02-09 |
| 2주차 - 네트워크 | project | 2025-02-25 |
| 3주차 - 스토리지 | project | 2025-02-16 |
| 4주차 - 관측 가능성 | project | 2025-02-23 |
| 3주차 - 다양한 노드 그룹 | project | 2025-02-24 |
| 4주차 - opentelemetry 데모 | project | 2025-03-01 |
| 4주차 - 네트워크 추가 | project | 2025-03-01 |
| 5주차 - 오토스케일링 | project | 2025-03-02 |
| 6주차 - 시큐리티 | project | 2025-03-09 |
| 7주차 - 모드, 노드 | project | 2025-03-16 |
| 8주차 - CICD | project | 2025-03-23 |
| 9주차 - 업그레이드 | project | 2025-03-30 |
| 10주차 - 시크릿 관리 | project | 2025-04-11 |
| 11주차 - ml infra | project | 2025-04-17 |
| 12주차 - aws lattice, gateway api | project | 2025-04-23 |
| 1W - EKS 설치 및 액세스 엔드포인트 변경 실습 | published | 2025-02-03 |
| 2W - 테라폼으로 환경 구성 및 VPC 연결 | published | 2025-02-11 |
| 2W - EKS VPC CNI 분석 | published | 2025-02-11 |
| 2W - ALB Controller, External DNS | published | 2025-02-15 |
| 3W - kubestr과 EBS CSI 드라이버 | published | 2025-02-21 |
| 3W - EFS 드라이버, 인스턴스 스토어 활용 | published | 2025-02-22 |
| 4W - 번외 AL2023 노드 초기화 커스텀 | published | 2025-02-25 |
| 4W - EKS 모니터링과 관측 가능성 | published | 2025-02-28 |
| 4W - 프로메테우스 스택을 통한 EKS 모니터링 | published | 2025-02-28 |
| 5W - HPA, KEDA를 활용한 파드 오토스케일링 | published | 2025-03-07 |
| 5W - Karpenter를 활용한 클러스터 오토스케일링 | published | 2025-03-07 |
| 6W - PKI 구조, CSR 리소스를 통한 api 서버 조회 | published | 2025-03-15 |
| 6W - api 구조와 보안 1 - 인증 | published | 2025-03-15 |
| 6W - api 보안 2 - 인가, 어드미션 제어 | published | 2025-03-16 |
| 6W - EKS 파드에서 AWS 리소스 접근 제어 | published | 2025-03-16 |
| 6W - EKS api 서버 접근 보안 | published | 2025-03-16 |
| 7W - 쿠버네티스의 스케줄링, 커스텀 스케줄러 설정 | published | 2025-03-22 |
| 7W - EKS Fargate | published | 2025-03-22 |
| 7W - EKS Automode | published | 2025-03-22 |
| 8W - 아르고 워크플로우 | published | 2025-03-30 |
| 8W - 아르고 롤아웃 | published | 2025-03-30 |
| 8W - 아르고 CD | published | 2025-03-30 |
| 8W - CICD | published | 2025-03-30 |
| 9W - EKS 업그레이드 | published | 2025-04-02 |
| 10W - Vault를 활용한 CICD 보안 | published | 2025-04-16 |
| 11주차 - EKS에서 FSx, Inferentia 활용하기 | published | 2025-05-11 |
| 11W - EKS에서 FSx, Inferentia 활용하기 | published | 2025-04-18 |
| 12W - VPC Lattice 기반 gateway api | published | 2025-04-27 |
| E-파드 마운팅 recursiveReadOnly | topic/explain | 2025-02-27 |
| S-vpc 설정이 eks 액세스 엔드포인트에 미치는 영향 | topic/shooting | 2025-02-07 |
| T-마운트 전파 Bidirectioal | topic/temp | 2025-02-28 |
참고
https://docs.aws.amazon.com/ko_kr/vpc/latest/privatelink/what-is-privatelink.html ↩︎
https://docs.aws.amazon.com/ko_kr/eks/latest/userguide/eks-architecture.html ↩︎
https://docs.aws.amazon.com/ko_kr/eks/latest/userguide/managed-node-groups.html ↩︎
https://docs.aws.amazon.com/ko_kr/eks/latest/userguide/fargate.html ↩︎
https://docs.aws.amazon.com/ko_kr/eks/latest/userguide/hybrid-nodes-overview.html ↩︎
https://docs.aws.amazon.com/ko_kr/eks/latest/userguide/eks-optimized-amis.html ↩︎
https://aws.amazon.com/blogs/containers/bottlerocket-a-year-in-the-life/ ↩︎
https://aws.amazon.com/ko/blogs/containers/a-deep-dive-into-simplified-amazon-eks-access-management-controls/ ↩︎
https://docs.aws.amazon.com/eks/latest/userguide/access-policy-permissions.html ↩︎
https://aws.amazon.com/ko/blogs/containers/a-deep-dive-into-simplified-amazon-eks-access-management-controls/ ↩︎
https://catalog.workshops.aws/eks-immersionday/en-US/access-management/3-kubernetes-groups ↩︎
https://aws.amazon.com/ko/blogs/containers/diving-into-iam-roles-for-service-accounts/ ↩︎